Domain-Driven Design
Domain-Driven Design is a development technique which focuses on understanding the customer’s problem domain. It not only contains a set of technical ideas, but it also consists of techniques to structure the creativity in the development process.
The key of Domain-Driven Design is understanding the customers needs, and also the environment in which the customer works. The problem which the to-be-written program should solve is called the problem domain, and in Domain-Driven Design, development is guided by the exploration of the problem domain.
While talking to the customer to understand his needs and wishes, the developer creates a model which reflects the current understanding of the problem. This model is called Domain Model because it should accurately reflect the problem domain of the customer. Then, the domain model is tested with real use-cases, trying to understand if it fits to the customer’s processes and way of working. Then, the model is refined again – and the whole process of discussion with the customer starts again. Thus, Domain-Driven Design is an iterative approach to software development.
Still, Domain-Driven Design is very pragmatic, as code is created very early on (instead of extensive requirements specifications); and real-world problems thus occur very early in the development process, where they can be easily corrected. Normally, it takes some iterations of model refinement until a domain model adequately reflects the problem domain, focusing on the important properties, and leaving out unimportant ones.
In the following sections, some core components of Domain-Driven Design are explained. It starts with an approach to create a ubiquitous language, and then focuses on the technical realization of the domain model. After that, it is quickly explained how Flow enables Domain-Driven Design, such that the reader gets a more practical understanding of it.
Note
We do not explain all details of Domain-Driven Design in this work, as only parts of it are important for the general understanding needed for this work. More information can be found at [Evans].
Creating a Ubiquitous Language
In a typical enterprise software project, a multitude of different roles are involved: For instance, the customer is an expert in his business, and he wants to use software to solve a certain problem for him. Thus, he has a very clear idea on the interactions of the to-be-created software with the environment, and he is one of the people who need to use the software on a daily basis later on. Because he has much knowledge about how the software is used, we call him the Domain Expert.
On the other hand, there are the developers who actually need to implement the software. While they are very skilled in applying certain technologies, they often are no experts in the problem domain. Now, developers and domain experts speak a very different language, and misconceptions happen very often.
To reduce miscommunication, a ubiquitous language should be formed, in which key terms of the problem domain are described in a language understandable to both the domain expert and the developer. Thus, the developers learn to use the correct language of the problem domain right from the beginning, and can express themselves in a better way when discussing with the domain expert. Furthermore, they should also use the ubiquitous language throughout all parts of the project: Not only in communication, design documents and documentation, but the key terms should also appear in the domain model. Names of classes, methods and properties are also part of the ubiquitous language.
By using the language of the domain expert also in the code, it is possible to discuss about difficult-to-specify functionality by looking at the code together with the domain expert. This is especially helpful for complex calculations or difficult-to-specify condition rules. Thus, the domain expert can decide whether the business logic was correctly implemented.
Creating a ubiquitous language involves creating a glossary, in which the key terms are explained in a way both understandable to the domain expert and the developer. This glossary is also updated throughout the project, to reflect new insights gained in the development process.
Modelling the domain
Now, while discussing the problem with the domain expert, the developer starts to create the domain model, and refines it step by step. Usually, UML is employed for that, which just contains the relevant information of the problem domain.
The domain model consists of objects (as DDD is a technique for object-oriented languages), the so-called Domain Objects.
There are two types of domain objects, called Entities and Value Objects. If a domain object has a certain identity which stays the same as the objects changes its state, the object is an entity. Otherwise, if the identity of an object is only defined from all properties, it is a value object. We will now explain these two types of objects in detail, including practical use-cases.
Furthermore, association mapping is explained, and aggregates are introduced as a way to further structure the code.
Entities
Entities have a unique identity, which stays the same despite of changes in the properties of the object. For example, a user can have a user name as identity, a student a matriculation ID. Although properties of the objects can change over time (for example the student changes his courses), it is still the same object. Thus, the above examples are entities.
The identity of an object is given by an immutable property or a combination of them. In some use-cases it can make a lot of sense to define identity properties in a way which is meaningful in the domain context: If building an application which interfaces with a package tracking system, the tracking ID of a package should be used as identity inside the system. Doing so will reduce the risk of inconsistent data, and can also speed up access.
For some domain objects like a Person, it is
highly dependent on the problem domain what should be used as
identity property. In an internet forum, the e-mail address is often
used as identity property for people, while when implementing an
e-government application, one might use the passport ID to uniquely
identify citizens (which nobody would use in the web forum because
its data is too sensitive).
In case the developer does not specify an identity property, the framework assigns a universally unique identifier (UUID) to the object at creation time.
It is important to stress that identity properties need to be set at object creation time, i.e. inside the constructor of an object, and are not allowed to change throughout the whole object lifetime. As we will see later, the object will be referenced using its identity properties, and a change of an identity property would effectively wipe one object and create a new one without updating dependent objects, leaving the system in an inconsistent state.
In a typical system, many domain objects will be entities. However, for some use-cases, another type is a lot better suited: Value objects, which are explained in the next section.
Value Objects
PHP provides several value types which it supports internally: Integer, float, string, float and array. However, it is often the case that you need more complex types of values inside your domain. These are being represented using value objects.
The identity of a value object is defined by all its properties. Thus, two objects are equal if all properties are equal. For instance, in a painting program, the concept of color needs to be somewhere implemented. A color is only represented through its value, for instance using RGB notation. If two colors have the same RGB values, they are effectively similar and do not need to be distinguished further.
Value objects do not only contain data, they can potentially contain very much logic, for example for converting the color value to another color space like HSV or CMYK, even taking color profiles into account.
As all properties of a value object are part of its identity,
they are not allowed to be changed after the object’s creation.
Thus, value objects are immutable. The only way
to “change” a value object is to create a new one using the old one
as basis. For example, there might be a method mix on
the Color object, which takes another
Color object and mixes both colors. Still, as the
internal state is not allowed to change, the mix method
will effectively return a new Color object containing
the mixed color values.
As value objects have a very straightforward semantic definition (similar to the simple data types in many programming languages), they can easily be created, cloned or transferred to other subsystems or other computers. Furthermore, it is clearly communicated that such objects are simple values.
Internally, frameworks can optimize the use of value objects by re-using them whenever possible, which can greatly reduce the amount of memory needed for applications.
Entity or Value Object?
An object can not be ultimately categorized into either being an entity or a value object – it depends greatly on the use case. An example illustrates this: For many applications which need to store an address, this address is clearly a value object - all properties like street, number, or city contribute to the identity of the object, and the address is only used as container for these properties.
However, if implementing an application for a postal service which should optimize letter delivery, not only the address, but also the person delivering to this location should be stored. This name of the postman does not belong to the identity of the object, and can change over time – a clear sign of Address being an entity in this case. So, generally it often depends on the use-case whether an object is an entity or value object.
People new to Domain-Driven Design often tend to overuse entities, as this is what people coming from a relational database background are used to.
So why not just use entities all the time? The design/architectural answer is: because a value object might just be more fitting your problem at hand. The technical answer is: because value objects are immutable and therefore avoid aliasing [1] problems, which are common cause of all kinds of bugs.
Associations
Now, after explaining the two types of domain objects, we will look at a particularly important implementation area: Associations between objects.
Domain objects have relationships between them. In the domain language, these relations are expressed often as follows: A consists of B, C has D, E processes F, G belongs to H. These relations are called associations in the domain model.
In the real world, relationships are often inherently bidirectional, are only active for a certain time span, and can contain further information. However, when modelling these relationships as associations, it is important to simplify them as much as possible, encoding only the relevant information into the domain model.
Especially complex to implement are bidirectional many-to-many relations, as they can be traversed in both directions, and consist of two lists of objects which have to be kept in sync manually in most programming languages (such as Java or PHP).
Still, especially in the first iterations of refining the domain model, many-to-many relations are very common. The following questions can help to simplify them:
Is the association relevant for the core functionality of the application? If it is only used in rare use cases and there is another way to receive the needed information, it is often better to drop the association altogether.
For bidirectional associations, can they be converted to unidirectional associations, because there is a main traversal direction? Traversing the other direction is still possible by querying the underlying persistence system.
Can the association be qualified more restrictively, for example by adding multiplicities on each side?
The more simple the association is, the more directly it can be mapped to code, and the more clear the intent is.
Aggregates
When building a complex domain model, it will contain a lot of
classes, all being on the same hierarchy level. However, often it is
the case that certain objects are parts of a bigger object. For
example, when modeling a Car domain object for a car
repair shop, it might make sense to also model the wheels and the
engine. As they are a part of the car, this understanding should be
also reflected in our model.
Such a part-whole relationship of closely related objects is called Aggregate. An aggregate contains a root, the so-called Aggregate Root, which is responsible for the integrity of the child-objects. Furthermore, the whole aggregate has only one identity visible to the outside: The identity of the aggregate root object. Thus, objects outside of the aggregate are only allowed to persistently reference the aggregate root, and not one of the inner objects.
For the Car example this means that a
ServiceStation object should not reference the engine
directly, but instead reference the Car through its
external identity. If it still needs access to the
engine, it can retrieve it through the Car
object.
These referencing rules effectively structure the domain model on a more fine-grained level, which reduces the complexity of the application.
Life cycle of objects
Objects in the real world have a certain life cycle. A car is built, then it changes during its lifetime, and in the end it is scrapped. In Domain-Driven Design, the life cycle of domain objects is very similar:

Simplified life cycle of objects
Because of performance reasons, it is not feasible to keep all
objects in memory forever. Some kind of persistent storage, like a
database, is needed. Objects which are not needed at the current point
in time should be persistently stored, and only transformed into
objects when needed. Thus, we need to expand the active
state from Simplified life cycle of objects to contain some more
substates. These are shown below:
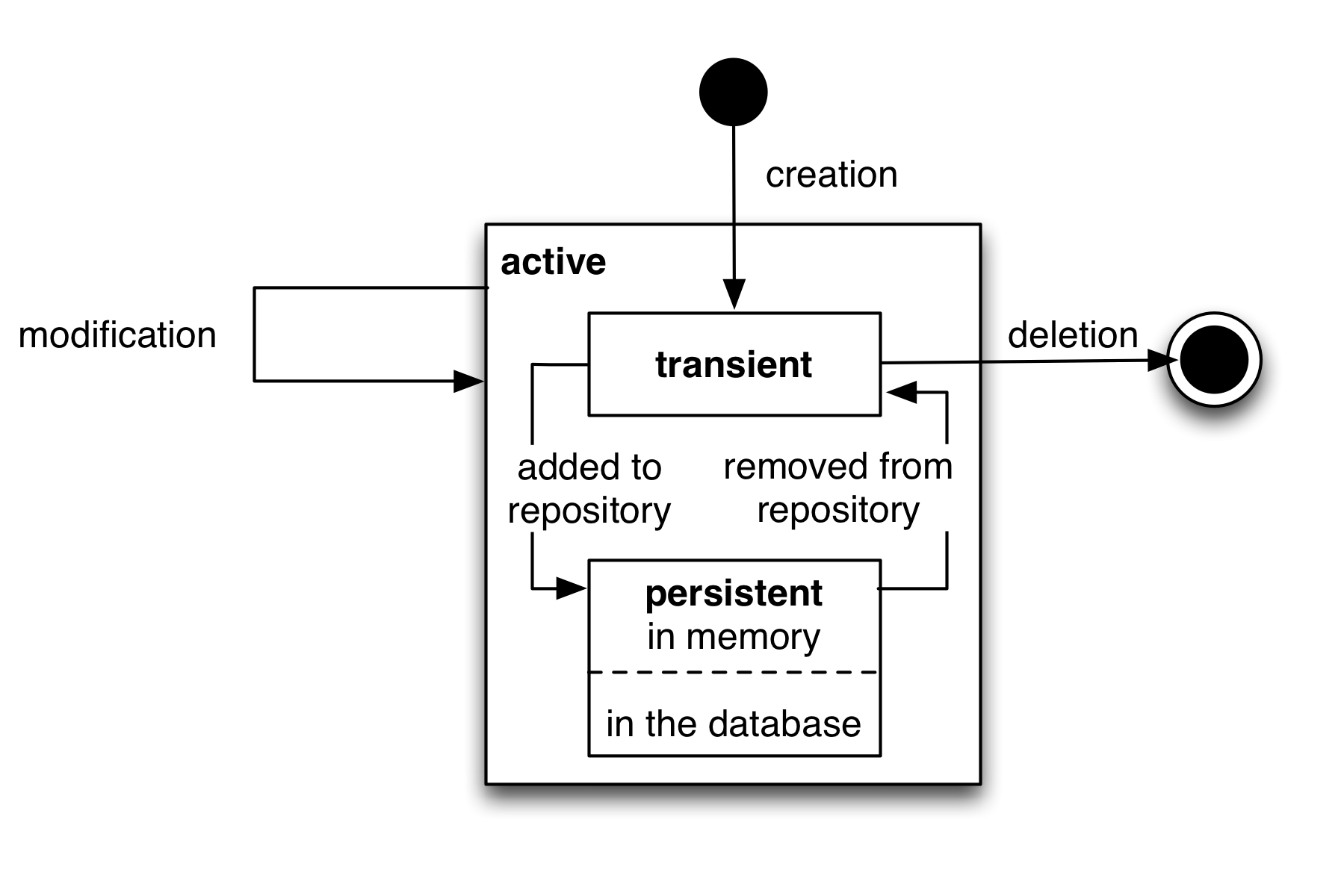
The real life cycle of objects
If an object is newly created, it is transient, so it is being deleted from memory at the end of the current request. If an object is needed permanently across requests, it needs to be transformed to a persistent object. This is the responsibility of Repositories, which allow to persistently store and retrieve domain objects.
So, if an object is added to a repository, this repository becomes responsible for saving the object. Furthermore, it is also responsible for persisting further changes to the object throughout its lifetime, automatically updating the database as needed.
For retrieving objects, repositories provide a query language. The repository automatically handles the database retrieval, and makes sure that each entity is only once in memory.
Despite the object being created and retrieved multiple times during its lifecycle, it logically continues to exist, even when it is stored in the database. It is only because of performance and safety reasons that is is not stored in main memory, but in a database. Thus, Domain-Driven Design distinguishes creation of an object from reconstitution from database: In the first case, the constructor is called, in the second case the constructor is not called as the object is only converted from another representation form.
In order to remove a persistent object, it needs to be removed from the repository responsible for it, and then at the end of the request, the object is transparently removed from the database.
For each aggregate, there is exactly one repository responsible which can be used to fetch the aggregate root object.
How Flow enables Domain-Driven Design
Flow is a web development framework written in PHP, with Domain-Driven Design as its core principle. We will now show in what areas Flow supports Domain-Driven Design.
First, the developer can directly focus on creating the domain model, using unit testing to implement the use-cases needed. While he is creating the domain model, he can use plain PHP functionality, without caring about any particular framework. The PHP domain model he creates just consists of plain PHP objects, with no base class or other magic functionality involved. Thus, he can fully concentrate on domain modelling, without thinking about infrastructure yet.
This is a core principle of Flow: All parts of it strive for maximum focus and cleanness of the domain model, keeping the developer focused on the correct implementation of it.
Furthermore, the developer can use source code annotations to attach metadata to classes, methods or properties. This functionality can be used to mark objects as entity or value object, and to add validation rules to properties. In the domain object below, a sample of such an annotated class is given. As PHP does not have a language construct for annotations, this is emulated by Flow by parsing the source code comments.
In order to mark a domain object as aggregate
root, only a repository has to be created for it, based on
a certain naming convention. Repositories are the easiest way to make domain
objects persistent, and Flow provides a base class containing generic
findBy* methods. Furthermore, it supports a
domain-specific language for building queries which can be used for
more complex queries, as shown in below in the AccountRepository.
Now, this is all the developer needs to do in order to persistently store domain objects. The database tables are created automatically, and all objects get a UUID assigned (as we did not specify an identity property).
A simple domain object being marked as entity, and validation:
/**
* @Flow\Entity
*/
class Account {
/**
* @var string
*/
protected $firstName;
/**
* @var string
*/
protected $lastName;
/**
* @var string
* @Flow\Validate(type="EmailAddress")
*/
protected $email;
... getters and setters as well as other functions ...
}
A simple repository:
class AccountRepository extends \Neos\Flow\Persistence\Repository {
// by extending from the base repository, there is automatically a
// findBy* method available for every property, i.e. findByFirstName("Sebastian")
// will return all accounts with the first name "Sebastian".
public function findByName($firstName, $lastName) {
$query = $this->createQuery();
$query->matching(
$query->logicalAnd(
$query->equals('firstName', $firstName),
$query->equals('lastName', $lastName)
)
);
return $query->execute();
}
}
From the infrastructure perspective, Flow is structured as MVC framework, with the model being the Domain-Driven Design techniques. However, also in the controller and the view layer, the system has a strong support for domain objects: It can transparently convert objects to simple types, which can then be sent to the client’s browser. It also works the other way around: Simple types will be converted to objects whenever possible, so the developer can deal with objects in an end-to-end fashion.
Furthermore, Flow has an Aspect-Oriented Programming framework at its core, which makes it easy to separate cross-cutting concerns. There is a security framework in place (built upon AOP) where the developer can declaratively define access rules for his domain objects, and these are enforced automatically, without any checks needed in the controller or the model.
There are a lot more features to show, like rapid prototyping support, dependency injection, a signal-slots system and a custom-built template engine, but all these should only aid the developer in focusing on the problem domain and writing decoupled and extensible code.