Persistence
This chapter explains how to use object persistence in Flow. To do this, it focuses on the persistence based on the Doctrine 2 ORM first. There is another mechanism available, called Generic persistence, which can be used to add your own persistence backends to Flow. It is explained separately later in the chapter.
Note
The Generic persistence is deprecated as of Flow 6.0 and will be dropped in Flow 7.0.
Tip
If you have experience with Doctrine 2 already, your knowledge can be applied fully in Flow. If you have not worked with Doctrine 2 in the past, it might be helpful to learn more about it, as that might clear up questions this documentation might leave open.
Introductory Example
Let’s look at the following example as an introduction to how Flow handles persistence. We have a domain model of a Blog, consisting of Blog, Post, Comment and Tag objects:

The objects of the Blog domain model
Connections between those objects are built (mostly) by simple references in PHP, as a
look at the addPost() method of the Blog class shows:
Example: The Blog’s addPost() method
/**
* @param \Neos\Blog\Domain\Model\Post $post
* @return void
*/
public function addPost(\Neos\Blog\Domain\Model\Post $post) {
$post->setBlog($this);
$this->posts->add($post);
}
The same principles are applied to the rest of the classes, resulting in an object tree of a blog object holding several posts, those in turn having references to their associated comments and tags.
But now we need to make sure the Blog and the data in it are still available the next
time we need them. In the good old days of programming you might have
added some ugly database calls all over the system at this point. In the currently
widespread practice of loving Active Record you’d still add save() methods to all or most
of your objects. But can it be even easier?
To access an object you need to hold some reference to it. You can get that reference by
creating an object or by following some reference to it from some object you already have.
This leaves you at a point where you need to find that “first object”. This is done by
using a Repository. A Repository is the librarian of your system, knowing about all the
objects it manages. In our model the Blog is the entry point to our object tree,
so we will add a BlogRepository, allowing us to find Blog instances by the criteria we need.
Now, before we can find a Blog, we need to create and save one. What we do is create the
object and add it to the BlogRepository. This will automagically persist your Blog
and you can retrieve it again later.
For all that magic to work as expected, you need to give some hints. This doesn’t mean you need to write tons of XML, a few annotations in your code are enough:
Example: Persistence-related annotations in the Blog class
namespace Neos\Blog\Domain\Model;
/**
* A Blog object
*
* @Flow\Entity
*/
class Blog {
/**
* @var string
* @Flow\Validate(type="Text")
* @Flow\Validate(type="StringLength", options={ "minimum"=1, "maximum"=80 })
* @ORM\Column(length=80)
*/
protected $title;
/**
* @var \Doctrine\Common\Collections\ArrayCollection<\Neos\Blog\Domain\Model\Post>
* @ORM\OneToMany(mappedBy="blog")
* @ORM\OrderBy({"date" = "DESC"})
*/
protected $posts;
...
}
The first annotation to note is the Entity annotation, which tells the persistence
framework it needs to persist Blog instances if they have been added to a Repository. In
the Blog class we have some member variables, they are persisted as well by default. The
persistence framework knows their types by looking at the @var annotation you use anyway
when documenting your code (you do document your code, right?).
The Column annotation on $title is an optimization since we allow only 80 chars
anyway. In case of the $posts property the persistence framework persists the objects held
in that ArrayCollection as independent objects in a one-to-many relationship. Apart from those
annotations your domain object’s code is completely unaware of the persistence infrastructure.
Let’s conclude by taking a look at the BlogRepository code:
Example: Code of a simple BlogRepository
use Neos\Flow\Annotations as Flow;
/**
* A BlogRepository
*
* @Flow\Scope("singleton")
*/
class BlogRepository extends \Neos\Flow\Persistence\Repository {
}
As you can see we get away with very little code by simply extending the Flow-provided
repository class, and still we already have methods like findAll() and even magic
calls like findOneBy<PropertyName>() available. If we need some specialized find
methods in our repository, we can make use of the query building API:
Example: Using the query building API in a Repository
/**
* A PostRepository
*/
class PostRepository extends \Neos\Flow\Persistence\Repository {
/**
* Finds posts by the specified tag and blog
*
* @param \Neos\Blog\Domain\Model\Tag $tag
* @param \Neos\Blog\Domain\Model\Blog $blog The blog the post must refer to
* @return \Neos\Flow\Persistence\QueryResultInterface The posts
*/
public function findByTagAndBlog(\Neos\Blog\Domain\Model\Tag $tag,
\Neos\Blog\Domain\Model\Blog $blog) {
$query = $this->createQuery();
return $query->matching(
$query->logicalAnd(
$query->equals('blog', $blog),
$query->contains('tags', $tag)
)
)
->setOrderings(array(
'date' => \Neos\Flow\Persistence\QueryInterface::ORDER_DESCENDING)
)
->execute();
}
}
If you like to do things the hard way you can get away with implementing
\Neos\Flow\Persistence\RepositoryInterface yourself, though that is
something the normal developer never has to do.
Note
With the query building API it is possible to query for properties of sub-entities easily via a dot-notation path. When querying multiple properties of a collection property, it is ambiguous if you want to select a single sub-entity with the given matching constraints, or multiple sub-entities which each matching a part of the given constraints.
Since 4.0 Flow will translate such a query to “find all entities where a single sub-entity matches all the constraints”, which is the more common case. If you intend a different querying logic, you should fall back to DQL or native SQL queries instead.
Basics of Persistence in Flow
On the Principles of DDD
From Evans, the rules we need to enforce include:
The root Entity has global identity and is ultimately responsible for checking invariants.
Root Entities have global identity. Entities inside the boundary have local identity, unique only within the Aggregate.
Value Objects do not have identity. They are only identified by the combination of their properties and are therefore immutable.
Nothing outside the Aggregate boundary can hold a reference to anything inside, except to the root Entity. The root Entity can hand references to the internal Entities to other objects, but they can only use them transiently (within a single method or block).
Only Aggregate Roots can be obtained directly with database queries. Everything else must be done through traversal.
Objects within the Aggregate can hold references to other Aggregate roots.
A delete operation must remove everything within the Aggregate boundary all at once.
When a change to any object within the Aggregate boundary is committed, all invariants of the whole Aggregate must be satisfied.
On the relationship between adding and retrieving
When you add() something to a repository and do a findAll() immediately
afterwards, you might be surprised: the freshly added object will not be found. This is
not a bug, but a decision we took on purpose. Here is why.
When you add an object to a repository, it is added to the internal identity map and will
be persisted later (when persistAll() is called). It is therefore still in a transient
state - but all query operations go directly to the underlying data storage, because we
need to check that anyway. So instead of trying to query the in-memory objects we decided
to ignore transient objects for queries 4.
If you need to query for objects you just created, feel free to have the
PersistenceManager injected and use persistAll() in your code.
How changes are persisted
When you add or remove an object to or from a repository, the object will be added to
or removed from the underlying persistence as expected upon persistAll. But what about
changes to already persisted objects? As we have seen, those changes are only persisted, if
the changed object is given to update on the corresponding repository.
Now, for objects that have no corresponding repository, how are changes persisted? In the same way you fetch those objects from their parent - by traversal. Flow follows references from objects managed in a repository (aggregate roots) for all persistence operations, unless the referenced object itself is an aggregate root.
When using the Doctrine 2 persistence, this is done by virtually creating cascade attributes
on the mapped associations. That means if you changed an object attached to some aggregate
root, you need to hand that aggregate root to update for the change to be persisted.
Safe request methods are read-only
According to the HTTP 1.1 specification, so called “safe request methods” (usually GET or HEAD requests) should not change your data on the server side and should be considered read-only. If you need to add, modify or remove data, you should use the respective request methods (POST, PUT, DELETE and PATCH).
Flow supports this principle because it helps making your application more secure
and perform better. In practice that means for any Flow application: if the current
request is a “safe request method”, the persistence framework will NOT trigger
persistAll() at the end of the script run.
You are free to call PersistenceManager->persistAll() manually or use allowed objects
if you need to store some data during a safe request (for example, logging some data
for your analytics).
Allowed objects
There are rare cases which still justify persisting objects during safe requests. For example, your application might want to generate thumbnails of images during a GET request and persist the resulting PersistentResource instances.
For these cases it is possible to allow specific objects via the Persistence Manager:
$this->persistenceManager->allowObject($thumbnail);
$this->persistenceManager->allowObject($thumbnail->getResource());
Be very careful and think twice before using this method since many security measures are not active during “safe” request methods.
Dealing with big result sets
If the amount of the stored data increases, receiving all objects using a findAll() may
consume a lot more memory than available. In this cases, you can use the findAllIterator().
This method returns an IterableResult over which you can iterate, getting only one object at a time:
$iterator = $this->postRepository->findAllIterator();
foreach ($this->postRepository->iterate($iterator) as $post) {
// Iterate over all posts
}
Conventions for File and Class Names
To allow Flow to detect the object type a repository is responsible for, certain conventions need to be followed:
Domain models should reside in a Domain/Model directory
Repositories should reside in a Domain/Repository directory and be named
<ModelName>RepositoryAside from
ModelversusRepositorythe qualified class class names should be the same for corresponding classesRepositories must implement
\Neos\Flow\Persistence\RepositoryInterface(which is already the case when extending\Neos\Flow\Persistence\Repositoryor\Neos\Flow\Persistence\Doctrine\Repository)
Example: Conventions for model and repository naming
\Neos
\Blog
\Domain
\Model
Blog
Post
\Repository
BlogRepository
PostRepository
Another way to bind a repository to a model is to define a class constant named
ENTITY_CLASSNAME in your repository and give it the desired model name as value. This
should be done only when following the conventions outlined above is not feasible.
Lazy Loading
Lazy Loading is a feature that can be equally helpful and dangerous when it comes to optimizing your application. Flow defaults to lazy loading when using Doctrine, i.e. it loads all the data in an object as soon as you fetch the object from the persistence layer but does not fetch data of associated objects. This avoids massive amounts of objects being reconstituted if you have a large object tree. Instead it defers property thawing in objects until the point when those properties are really needed.
The drawback of this: If you access associated objects, each access will fire a request to the persistent storage now. So there might be situations when eager loading comes in handy to avoid excessive database roundtrips. Eager loading is the default when using the Generic persistence mechanism and can be achieved for the Doctrine 2 ORM by using join operations in DQL or specifying the fetch mode in the mapping configuration.
Doctrine Persistence
Doctrine 2 ORM is used by default in Flow. Aside from very few internal changes it consists of the regular Doctrine ORM, DBAL, Migrations and Common libraries and is tied into Flow by some glue code and (most important) a custom annotation driver for metadata consumption.
Requirements and restrictions
There are some rules imposed by Doctrine (and/or Flow) you need to follow for your entities (and value objects). Most of them are good practice anyway, and thus are not really restrictions.
Entity classes must not be
finalor containfinalmethods.Persistent properties of any entity class should always be
protected, notpublic, otherwise lazy-loading might not work as expected.Implementing
__clone()or__wakeup()is not a problem with Flow, as the instances always have an identity. If using your own identity properties, you must wrap any code you intend to run in those methods in an identity check.Entity classes in a class hierarchy that inherit directly or indirectly from one another must not have a mapped property with the same name.
Entities cannot use
func_get_args()to implement variable parameters. The proxies generated by Doctrine do not support this for performance reasons and your code might actually fail to work when violating this restriction.
Persisted instance variables must be accessed only from within the entity instance itself, not by clients of the entity. The state of the entity should be available to clients only through the entity’s methods, i.e. getter/setter methods or other business methods.
Collection-valued persistent fields and properties must be defined in terms of the
Doctrine\Common\Collections\Collection interface. The collection implementation type
may be used by the application to initialize fields or properties before the entity is
made persistent. Once the entity becomes managed (or detached), subsequent access must
happen through the interface type.
Metadata mapping
The Doctrine 2 ORM needs to know a lot about your code to be able to persist it. Natively Doctrine 2 supports the use of annotations, XML, YAML and PHP to supply that information. In Flow, only annotations are supported, as this aligns with the philosophy behind the framework.
Annotations for the Doctrine Persistence
The following table lists the most common annotations used by the persistence framework with their name, scope and meaning:
Persistence-related code annotations
Annotation |
Scope |
Meaning |
|---|---|---|
|
Class |
Declares a class as an Entity. |
|
Class |
Declares a class as a Value Object, allowing the persistence framework to reuse an existing object if one exists. |
|
Variable |
Allows to take influence on the column actually generated for this property in the database. Particularly useful with string properties to limit the space used or to enable storage of more than 255 characters. |
|
Variable |
Defines the type of object associations, refer to the
Doctrine 2 documentation for details. The most obvious
difference to plain Doctrine 2 is that the
The |
|
Variable |
Is used to detect the type a variable has. For collections, the type is given in angle brackets. |
|
Variable |
Makes the persistence framework ignore the variable. Neither will it’s value be persisted, nor will it be touched during reconstitution. |
|
Variable |
Marks the variable as being relevant for determining the identity of an object in the domain. For all class properties marked with this, a (compound) unique index will be created in the database. |
Doctrine supports many more annotations, for a full reference please consult the Doctrine 2 ORM documentation.
On Value Object handling with Doctrine
Doctrine 2.5 supports value objects in the form of embeddable objects 5. This means that the value object properties will directly be included in the parent entities table schema. However, Doctrine doesn’t currently support embeddable collections 6. Therefore, Flow supports two types of value objects: readonly entities and embedded
By default, Flow will use the readonly version, as that is more flexible and also works in collections. However, this comes with some architectural drawbacks, because the value object thereby is actually treated like an entity with an identifier, which contradicts the very definition of a value object.
The behaviour of non-embedded Value Objects is as follows:
Value Objects are marked immutable as with the
ReadOnlyannotation of Doctrine.Each Value Object will internally be referenced by an identifier that is automatically generated from it’s property values after construction.
If the relation to a Value Object is annotated as OneTo* or ManyTo*, the Value Object will be persisted in it’s own table. Otherwise, unless you override the type using
ColumnValue Objects will be stored as serialized object in the database.Upon persisting Value Objects already present in the underlying database they will be deduplicated by being referenced through the identifier.
For cases where a *ToMany relation to a Value Object is not needed, the embedded form is the
more natural way to persist value objects. You can therefore set the annotation property
embedded to true, which will cause the Value Object to be embedded inside all Entities
that reference it.
The behaviour of embedded Value Objects is as follows:
Every entity having a property of type embedded Value Object will get all the properties of the Value Object included in it’s schema.
Unless you specify the
EmbeddedAnnotation on the relation property, the schema prefix will be the property name.
/**
* @Flow\ValueObject(embedded=true)
*/
class ValueObject {
...
}
class SomeEntity {
/**
* @var ValueObject
*/
protected $valueObject;
Custom Doctrine mapping types
Doctrine provides a way to develop custom mapping types as explained in the documentation ([#doctrineMappingTypes]).
Registration of those types in a Flow application is done through settings:
Neos:
Flow:
persistence:
doctrine:
# DBAL custom mapping types can be registered here
dbal:
mappingTypes:
'mytype':
dbType: 'db_mytype'
className: 'Acme\Demo\Doctrine\DataTypes\MyType'
The custom type can then be used:
class SomeModel {
/**
* Some custom type property
*
* @ORM\Column(type="mytype")
* @var string
*/
protected $mytypeProperty;
On the Doctrine Event System
Doctrine provides a flexible event system to allow extensions to plug into different parts
of the persistence. Therefore two methods to get notification of doctrine events are
possible - through the EventSubscriber interface and registering EventListeners.
Flow allows for easily registering both with Doctrine through the configuration settings
Neos.Flow.persistence.doctrine.eventSubscribers and Neos.Flow.persistence.doctrine.eventListeners
respectively. EventSubscribers need to implement the Doctrine\Common\EventSubscriber Interface
and provide a list of the events they want to subscribe to. EventListeners need to be configured
for the events they want to listen on, but do not need to implement any specific Interface.
See the documentation (7) for more information on the Doctrine Event System.
Example: Configuration for Doctrine EventSubscribers and EventListeners:
Neos:
Flow:
persistence:
doctrine:
eventSubscribers:
- 'Foo\Bar\Events\EventSubscriber'
eventListeners:
-
events: ['onFlush', 'preFlush', 'postFlush']
listener: 'Foo\Bar\Events\EventListener'
On the Doctrine Filter System
Doctrine provides a filter system that allows developers to add SQL to the conditional clauses of queries, regardless the place where the SQL is generated (e.g. from a DQL query, or by loading).
Flow allows for easily registering Filters with Doctrine through the
configuration setting Neos.Flow.persistence.doctrine.filters.
Example: Configuration for Doctrine Filters:
Neos:
Flow:
persistence:
doctrine:
filters:
'my-filter-name': 'Acme\Demo\Filters\MyFilter'
See the Doctrine documentation (8) for more information on the Doctrine Filter System.
Note
If you create a filter and run into fatal errors caused by overriding a final
__construct() method in one of the Doctrine classes, you need to add
@Flow\Proxy(false) to your filter class to prevent Flow from building a proxy,
which causes this error.
Warning
Custom SqlFilter implementations - watch out for data privacy issues!
If using custom SqlFilters, you have to be aware that the SQL filter is cached by doctrine, thus your SqlFilter might not be called as often as you might expect. This may lead to displaying data which is not normally visible to the user!
Basically you are not allowed to call setParameter inside addFilterConstraint; but setParameter must be called before the SQL query is actually executed. Currently, there’s no standard Doctrine way to provide this; so you manually can receive the filter instance from $entityManager->getFilters()->getEnabledFilters() and call setParameter() then.
Alternatively, you can register a global context object in Neos.Flow.aop.globalObjects and use it to provide additional identifiers for the caching by letting these global objects implement CacheAwareInterface; effectively segregating the Doctrine cache some more.
Custom Doctrine DQL functions
Doctrine allows custom functions for use in DQL. In order to configure these for the use in Flow, use the following Settings:
Neos:
Flow:
persistence:
doctrine:
dql:
customStringFunctions:
'SOMEFUNCTION': 'Acme\Demo\Persistence\Ast\SomeFunction'
customNumericFunctions:
'FLOOR': 'Acme\Demo\Persistence\Ast\Floor'
'CEIL': 'Acme\Demo\Persistence\Ast\Ceil'
customDatetimeFunctions:
'UTCDIFF': 'Acme\Demo\Persistence\Ast\UtcDiff'
See the Doctrine documentation (2) for more information on the Custom DQL functions.
Metadata and Query Cache
Flow automatically configures a cache for the Doctrine metadata, the used cache
is the Flow_Persistence_Doctrine cache. The result cache is configured as well,
the used cache is Flow_Persistence_Doctrine_Results.
This happens in \Neos\Flow\Persistence\Doctrine\EntityManagerConfiguration::applyCacheConfiguration(…)
The use of the result cache can be enabled globally using the Neos.Flow.persistence.cacheAllQueryResults
setting or on a per-query level by using the $cacheResult parameter of the Query::execute() method.
See https://www.doctrine-project.org/projects/doctrine-dbal/en/2.13/reference/caching.html for more information.
Using Doctrine’s Second Level Cache
Doctrine provides a second level cache that further improves performance of relation queries beyond the result query cache.
See the Doctrine documentation (3) for more information on the second level cache.
Flow allows you to enable and configure the second level cache through the configuration setting
Neos.Flow.persistence.doctrine.secondLevelCache.
Example: Configuration for Doctrine second level cache:
Neos:
Flow:
persistence:
doctrine:
secondLevelCache:
enable: true
defaultLifetime: 3600
regions:
'my_entity_region': 7200
Customizing Doctrine EntityManager
For any cases that are not covered with the above options, Flow provides two convenient signals to hook into the setup of the doctrine EntityManager.
The beforeDoctrineEntityManagerCreation signal provides you with the DBAL connection, the doctrine configuration and EventManager classes, that you can change before the actual EntityManager is instantiated.
The afterDoctrineEntityManagerCreation signal provides the doctrine configuration and EntityManager instance, in order to to further set options.
Note
All above configuration options through the settings are actually implemented as slots to the before mentioned signals. If you want to take some look how this works, check the NeosFlowPersistenceDoctrineEntityManagerConfiguration class.
Differences between Flow and plain Doctrine
The custom annotation driver used by Flow to collect mapping information from the code makes a number of things easier, compared to plain Doctrine 2.
EntityrepositoryClasscan be left out, if you follow the naming rules for your repository classes explained above.Tablenamedoes not default to the unqualified entity classname, but a name is generated from class name, package key and more elements to make it unique.IdCan be left out, as it is automatically generated, this means you also do not need
@GeneratedValue. Every entity will get a property injected that is filled with an UUID upon instantiation and used as technical identifier.If an
@Idannotation is found, it is of course used as is and no magic will happen.ColumnCan usually be left out altogether, as the vital type information can be read from the
@varannotation on a class member.Important
Since PHP does not differentiate between short and long strings, but databases do, you must use
@Column(type="text")if you intend to store more than 255 characters in a string property.OneToOne,OneToMany,ManyToOne,ManyToManytargetEntitycan be omitted, it is read from the@varannotation on the property. Relations to Value Objects will becascadepersistby default and relations to non aggregate root entities will becascadeallby default.JoinTable,JoinColumnCan usually be left out completely, the needed information is gathered automatically But when using a self-referencing association, you will need to help Flow a little, so it doesn’t generate a join table with only one column.
Example: JoinTable annotation for a self-referencing annotation
/** * @var \Doctrine\Common\Collections\ArrayCollection<\Neos\Blog\Domain\Model\Post> * @ORM\ManyToMany * @ORM\JoinTable(inverseJoinColumns={@ORM\JoinColumn(name="related_id")}) */ protected $relatedPosts;
Without this, the created table would not contain two columns but only one, named after the identifiers of the associated entities - which is the same in this case.
DiscriminatorColumn,DiscriminatorMapCan be left out, as they are automatically generated.
The generation of this metadata is slightly more expensive compared to the plain Doctrine
AnnotationDriver, but since this information can be cached after being generated once,
we feel the gain when developing outweighs this easily.
Tip
Anything you explicitly specify in annotations regarding Doctrine, has precedence over the automatically generated metadata. This can be used to fully customize the mapping of database tables to models.
Here is an example to illustrate the things you can omit, due to the automatisms in the Flow annotation driver.
Example: Annotation equivalents in Flow and plain Doctrine 2
An entity with only the annotations needed in Flow:
/**
* @Flow\Entity
*/
class Post {
/**
* @var \Neos\Blog\Domain\Model\Blog
* @ORM\ManyToOne(inversedBy="posts")
*/
protected $blog;
/**
* @var string
* @ORM\Column(length=100)
*/
protected $title;
/**
* @var \DateTime
*/
protected $date;
/**
* @var string
* @ORM\Column(type="text")
*/
protected $content;
/**
* @var \Doctrine\Common\Collections\ArrayCollection<\Neos\Blog\Domain\Model\Comment>
* @ORM\OneToMany(mappedBy="post")
* @ORM\OrderBy({"date" = "DESC"})
*/
protected $comments;
The same code with all annotations needed in plain Doctrine 2 to result in the same metadata:
/**
* @ORM\Entity(repositoryClass="Neos\Blog\Domain\Model\Repository\PostRepository")
* @ORM\Table(name="blog_post")
*/
class Post {
/**
* @var string
* @ORM\Id
* @ORM\Column(name="persistence_object_identifier", type="string", length=40)
*/
protected $Persistence_Object_Identifier;
/**
* @var \Neos\Blog\Domain\Model\Blog
* @ORM\ManyToOne(targetEntity="Neos\Blog\Domain\Model\Blog", inversedBy="posts")
* @ORM\JoinColumn(name="blog_blog", referencedColumnName="persistence_object_identifier")
*/
protected $blog;
/**
* @var string
* @ORM\Column(type="string", length=100)
*/
protected $title;
/**
* @var \DateTime
* @ORM\Column(type="datetime")
*/
protected $date;
/**
* @var string
* @ORM\Column(type="text")
*/
protected $content;
/**
* @var \Doctrine\Common\Collections\ArrayCollection<\Neos\Blog\Domain\Model\Comment>
* @ORM\OneToMany(targetEntity="Neos\Blog\Domain\Model\Comment", mappedBy="post",
cascade={"all"}, orphanRemoval=true)
* @ORM\OrderBy({"date" = "DESC"})
*/
protected $comments;
Schema management
Doctrine offers a Migrations system as an add-on part of its DBAL for versioning of database schemas and easy deployment of changes to them. There exist a number of commands in the Flow CLI toolchain to create and deploy migrations.
A Migration is a set of commands that bring the schema from one version to the next. In the simplest form that means creating a new table, but it can be as complex as renaming a column and converting data from one format to another along the way. Migrations can also be reversed, so one can migrate up and down.
Each Migration is represented by a PHP class that contains the needed commands. Those classes come with the package they relate to, they have a name that is based on the time they were created. This allows correct ordering of migrations coming from different packages.
Query the schema status
To learn about the current schema and migration status, run the following command:
$ ./flow flow:doctrine:migrationstatus
This will produce output similar to the following, obviously varying depending on the actual state of schema and active packages:
Example: Migration status report
== Configuration
>> Name: Doctrine Database Migrations
>> Database Driver: pdo_mysql
>> Database Name: flow
>> Configuration Source: manually configured
>> Version Table Name: flow_doctrine_migrationstatus
>> Migrations Namespace: Neos\Flow\Persistence\Doctrine\Migrations
>> Migrations Target Directory: /path/to/Data/DoctrineMigrations
>> Current Version: 0
>> Latest Version: 2011-06-13 22:38:37 (20110613223837)
>> Executed Migrations: 0
>> Available Migrations: 1
>> New Migrations: 1
== Migration Versions
>> 2011-06-13 22:38:37 (20110613223837) not migrated
Whenever a version number needs to be given to a command, use the short form as shown in parentheses in the output above. The migrations directory in the output is only used when creating migrations, see below for details on that.
Deploying migrations
On a pristine database it is very easy to create the tables needed with the following command:
$ ./flow flow:doctrine:migrate
This will result in output that looks similar to the following:
Migrating up to 20110613223837 from 0
++ migrating 20110613223837
-> CREATE TABLE flow_resource_resourcepointer (hash VARCHAR(255) NOT NULL, PRIMARY KEY(hash)) ENGINE = InnoDB
-> ALTER TABLE flow_resource_resource ADD FOREIGN KEY (flow_resource_resourcepointer) REFERENCES flow_resource_resourcepointer(hash)
++ migrated (1.31s)
------------------------
++ finished in 1.31
++ 1 migrations executed
++ 6 sql queries
This will deploy all migrations delivered with the currently active packages to the configured database. During that process it will display all the SQL statements executed and a summary of the deployed migrations at the and. You can do a dry run using:
$ ./flow flow:doctrine:migrate --dry-run
This will result in output that looks similar to the following:
Executing dry run of migration up to 20110613223837 from 0
++ migrating 20110613223837
-> CREATE TABLE flow_resource_resourcepointer (hash VARCHAR(255) NOT NULL, PRIMARY KEY(hash)) ENGINE = InnoDB
-> ALTER TABLE flow_resource_resource ADD FOREIGN KEY (flow_resource_resourcepointer) REFERENCES flow_resource_resourcepointer(hash)
++ migrated (0.09s)
------------------------
++ finished in 0.09
++ 1 migrations executed
++ 6 sql queries
to see the same output but without any changes actually being done to the database. If you want to inspect and possibly adjust the statements that would be run and deploy manually, you can write to a file:
$ ./flow flow:doctrine:migrate --path <where/to/write/the.sql>
This will result in output that looks similar to the following:
Writing migration file to "<where/to/write/the.sql>"
Important
When actually making manual changes, you need to keep the flow_doctrine_migrationstatus
table updated as well! This is done with the flow:doctrine:migrationversion command.
It takes a --version option together with either an --add or --delete flag to
add or remove the given version in the flow_doctrine_migrationstatus table. It does
not execute any migration code but simply marks the given version as migrated or not.
Reverting migrations
The migrate command takes an optional --version option. If given, migrations will be
executed up or down to reach that version. This can be used to revert changes, even
completely:
$ ./flow flow:doctrine:migrate --version <version> --dry-run
This will result in output that looks similar to the following:
Executing dry run of migration down to 0 from 20110613223837
-- reverting 20110613223837
-> ALTER TABLE flow_resource_resource DROP FOREIGN KEY
-> DROP TABLE flow_resource_resourcepointer
-> DROP TABLE flow_resource_resource
-> DROP TABLE flow_security_account
-> DROP TABLE flow_resource_securitypublishingconfiguration
-> DROP TABLE flow_policy_role
-- reverted (0.05s)
------------------------
++ finished in 0.05
++ 1 migrations executed
++ 6 sql queries
Executing or reverting a specific migration
Sometimes you need to deploy or revert a specific migration, this is possible as well.
$ ./flow flow:doctrine:migrationexecute --version <20110613223837> --direction <direction> --dry-run
This will result in output that looks similar to the following:
-- reverting 20110613223837
-> ALTER TABLE flow_resource_resource DROP FOREIGN KEY
-> DROP TABLE flow_resource_resourcepointer
-> DROP TABLE flow_resource_resource
-> DROP TABLE flow_security_account
-> DROP TABLE flow_resource_securitypublishingconfiguration
-> DROP TABLE flow_policy_role
-- reverted (0.41s)
As you can see you need to specify the migration --version you want to execute. If you
want to revert a migration, you need to give the --direction as shown above, the
default is to migrate “up”. The --dry-run and and --output options work as with
flow:doctrine:migrate.
Creating migrations
Migrations make the schema match when a model changes, but how are migrations created? The basics are simple, but rest assured that database details and certain other things make sure you’ll need to practice… The command to scaffold a migration is the following:
$ ./flow flow:doctrine:migrationgenerate
This will result in output that looks similar to the following:
Generated new migration class!
Do you want to move the migration to one of these packages?
[0 ] Don't Move
[1 ] Neos.Diff
[2 ] …
You should pick the package that your new migration covers, it will then be moved as requested. The command will output the path to generated migration and suggest some next steps to take.
Important
If you decide not to move the file, it will be put into Data/DoctrineMigrations/.
That directory is only used when creating migrations. The migrations visible to the system
are read from Migrations/<DbPlatForm> in each package. The <DbPlatform> represents the
target platform, e.g. Mysql (as in Doctrine DBAL but with the first character uppercased).
Looking into that file reveals a basic migration class already filled with the differences detected between the current schema and the current models in the system:
Example: Migration generated based on schema/model differences
namespace Neos\Flow\Persistence\Doctrine\Migrations;
use Doctrine\DBAL\Migrations\AbstractMigration,
Doctrine\DBAL\Schema\Schema;
/**
* Auto-generated Migration: Please modify to your need!
*/
class Version20110624143847 extends AbstractMigration {
/**
* @param Schema $schema
* @return void
*/
public function up(Schema $schema) {
// this up() migration is autogenerated, please modify it to your needs
$this->abortIf($this->connection->getDatabasePlatform()->getName() != "mysql");
$this->addSql("CREATE TABLE party_abstractparty (…) ENGINE = InnoDB");
}
/**
* @param Schema $schema
* @return void
*/
public function down(Schema $schema) {
// this down() migration is autogenerated, please modify it to your needs
$this->abortIf($this->connection->getDatabasePlatform()->getName() != "mysql");
$this->addSql("DROP TABLE party_abstractparty");
}
}
To create an empty migration skeleton, pass --diff-against-current 0 to the command.
After you generated a migration, you will probably need to clean up a little, as there might be differences being picked up that are not useful or can be optimized. An example is when you rename a model: The migration will drop the old table and create the new one, but what you want instead is to rename the table. Also you must to make sure each finished migration file only deals with one package and then move it to the Migrations directory in that package. This way different packages can be mixed and still a reasonable migration history can be built up.
Ignoring tables
For tables that are not known to the schema because they are code-generated or come from a
different system sharing the same database, the flow:doctrine:migrationgenerate command
will generate corresponding DROP TABLE statements.
In this case you can use the --filter-expression flag to generate migrations only for tables
matching the given pattern:
$ ./flow flow:doctrine:migrationgenerate --filter-expression '^your_package_.*'
Will only affect tables starting with “your_package_”.
To permanently skip certain tables the ignoredTables setting can be used:
Neos:
Flow:
persistence:
doctrine:
migrations:
ignoredTables:
'autogenerated_.*': TRUE
'wp_.*: TRUE
Will ignore table starting with “autogenerated_” or “wp_” by default (the –filter-expression flag overrules this setting).
Schema updates without migrations
Migrations are the recommended and preferred way to bring your schema up to date. But there might be situations where their use is not possible (e.g. no migrations are available yet for the RDBMS you are using) or not wanted (because of, um… something). The there are two simple commands you can use to create and update your schema.
To create the needed tables you can call ./flow flow:doctrine:create and it will
create all needed tables. If any target table already exists, an error will be the
result.
To update an existing schema to match with the current mapping metadata (i.e. the current
model structure), use ./flow flow:doctrine:update to have missing items (fields,
indexes, …) added. There is a flag to disable the safe mode used by default. In safe mode,
Doctrine tries to keep existing data as far as possible, avoiding lossy actions.
Warning
Be careful, the update command might destroy data, as it could drop tables and fields
irreversibly.
It also doesn’t respect the ignoredTables settings (see previous section).
Both commands also support --output <write/here/the.sql> to write the SQL
statements to the given file instead of executing it.
Tip
If you created or updated the schema this way, you should afterwards execute
flow:doctrine:migrationversion --version all --add to avoid migration
errors later.
Doctrine Connection Wrappers - Primary/Replica Connections
Doctrine 2 allows to create Connection wrapper classes, that change the way Doctrine connects
to your database. A common use case is a primary/replica setup, with one primary server
and several read replicas that share the load for all reading queries.
Doctrine already provides a wrapper for such a connection and you can configure Flow to use
that connection wrapper by setting the following options in your packages Settings.yaml:
Neos:
Flow:
persistence:
backendOptions:
wrapperClass: 'Doctrine\DBAL\Connections\PrimaryReadReplicaConnection'
primary:
host: '127.0.0.1' # adjust to your master database host
dbname: 'master' # adjust to your database name
user: 'user' # adjust to your database user
password: 'pass' # adjust to your database password
replicas:
replica1:
host: '127.0.0.1' # adjust to your slave database host
dbname: 'replica1' # adjust to your database name
user: 'user' # adjust to your database user
password: 'pass' # adjust to your database password
Note
In doctrine/dbal versions lower then 2.11 the wrapper class was named MasterSlaveConnection, so you need to adjust to that if you are such a version.
With this setup, Doctrine will use one of the replica connections picked once per request randomly for all queries until the first writing query (e.g. insert or update) is executed. From that point on the primary server will be used solely. This is to solve the problems of replication lag and possibly inconsistent query results.
Tip
You can also setup the primary database as a replica, if you want to also use it for load-balancing reading queries. However, this might lead to higher load on the primary database and should be well observed.
Known issues
When using PostgreSQL the use of the
object, andarraymapping types is not possible, this is caused by Doctrine usingserialize()to prepare data that is stored in text column (contained zero bytes truncate the string and lead to error during hydration). 9The Flow mapping types
flow_json_arrayandobjectarrayprovide solutions for this.When using PostgreSQL the use of the
json_arraymapping type can lead to issues when queries need comparisons on such columns (e.g. when grouping or doing distinct queries), because thejsontype used by Doctrine doesn’t support comparisons.The Flow mapping type
flow_json_arrayuses thejsonbtype available as of PostgreSQL 9.4, circumventing this restriction.
Generic Persistence
What is now called Generic Persistence, used to be the only persistence layer in Flow. Back in those days there was no ORM available that fit our needs. That being said, with the advent of Doctrine 2, your best bet as a PHP developer is to use that instead of any home-brewn ORM.
Note
The Generic persistence is deprecated as of Flow 6.0 and will be dropped in Flow 7.0.
When your target is not a relational database, things look slightly different, which is why the “old” code is still available for use, primarily by alternative backends like the ones for CouchDB or Solr, that are available. Using the Generic persistence layer to target a RDBMS is still possible, but probably only useful for rare edge cases.
Switching to Generic Persistence
To switch to Generic persistence you need to configure Flow like this.
Objects.yaml:
Neos\Flow\Persistence\PersistenceManagerInterface:
className: 'Neos\Flow\Persistence\Generic\PersistenceManager'
Neos\Flow\Persistence\QueryResultInterface:
scope: prototype
className: 'Neos\Flow\Persistence\Generic\QueryResult'
Settings.yaml:
Flow:
persistence:
doctrine:
enable: FALSE
When installing generic backend packages, like CouchDB, the needed object configuration should be contained in them, for the connection settings, consult the package’s documentation.
Metadata mapping
The persistence layer needs to know a lot about your code to be able to persist it. In Flow, the needed data is given in the source code through annotations, as this aligns with the philosophy behind the framework.
Annotations for the Generic Persistence
The following table lists all annotations used by the persistence framework with their name, scope and meaning:
Persistence-related code annotations
Annotation |
Scope |
Meaning |
|---|---|---|
|
Class |
Declares a class as an Entity. |
|
Class |
Declares a class as a Value Object, allowing the persistence framework to reuse an existing object if one exists. |
|
Variable |
Is used to detect the type a variable has. |
|
Variable |
Makes the persistence framework ignore the variable. Neither will it’s value be persisted, nor will it be touched during reconstitution. |
|
Variable |
Marks the variable as being relevant for determining the identity of an object in the domain. |
|
Class, Variable |
When reconstituting the value of this property will be
loaded only when the property is used. Note: This is only
supported for properties of type |
Enabling Lazy Loading
If a class should be able to be lazy loaded by the PDO backend, you need to annotate it
with @lazy in the class level docblock. This is done to avoid creating proxy classes
for objects that should never be lazy loaded anyway. As soon as that annotation is found,
AOP is used to weave lazy loading support into your code that intercepts all method calls
and initializes the object before calling the expected method. Such a proxy class is a
subclass of your class, as such it work fine with type hinting and checks and can be used
the same way as the original class.
To actually mark a property for lazy loading, you need to add the @lazy annotation to
the property docblock in your code. Then the persistence layer will skip loading the data
for that object and the object properties will be thawed when the object is actually used.
How @lazy annotations interact
Class |
Property |
Effect |
|---|---|---|
|
|
The class’ instances will be lazy loadable, and properties of that type will be populated with a lazy loading proxy. |
|
none |
The class’ instances will be lazy loadable, but that possibility will not be used. |
none |
|
Properties of type How and if lazy-loading is handled by alternative backends is up to the implementation. |
Schema management
Whether other backends implement automatic schema management is up to the developers, consult the documentation of the relevant backend for details.
Inside the Generic Persistence
To the domain code the persistence handling transparent, aside from the need to add a few annotations. The custom repositories are a little closer to the inner workings of the framework, but still the inner workings are very invisible. This is how it is supposed to be, but a little understanding of how persistence works internally can help understand problems and develop more efficient client code.
Persisting a Domain Object
After an object has been added to a repository it will be seen when Flow calls
persistAll() at the end of a script run. Internally all instances implementing the
\Neos\Flow\Persistence\RepositoryInterface will be fetched and asked for the objects
they hold. Those will then be handed to the persistence backend in use and processed by
it.
Flow defines interfaces for persistence backends and queries, the details of how objects are persisted and queried are up to the persistence backend implementation. Have a look at the documentation of the respective package for more information. The following diagram shows (most of) the way an object takes from creation until it is persisted when using the suggested process:
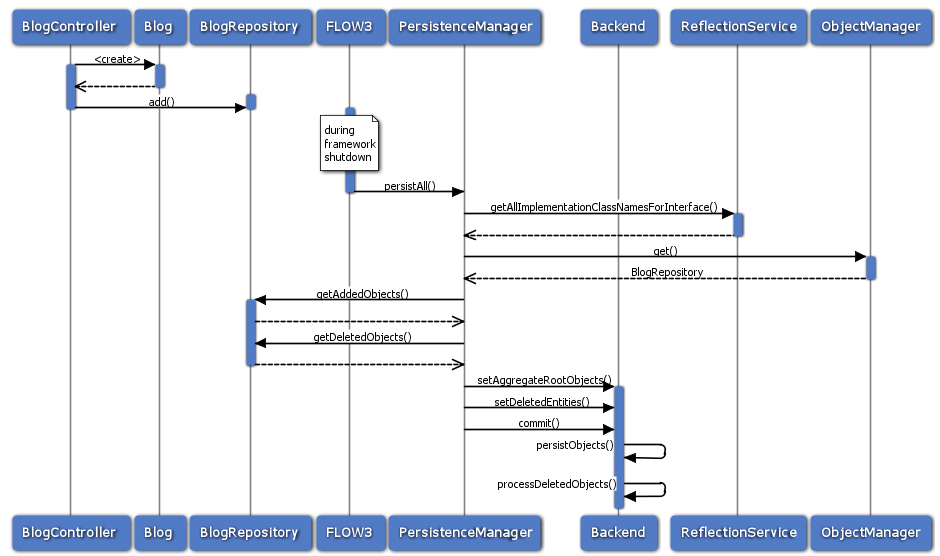
Object persistence process
Keep in mind that the diagram omits some details like dirty checking on objects and how exactly objects and their properties are stored.
Querying the Storage Backend
As we saw in the introductory example there is a query mechanism available that provides easy fetching of objects through the persistence framework. You ask for instances of a specific class that match certain filters and get back an array of those reconstituted objects. Here is a diagram of the internal process when using the suggested process:
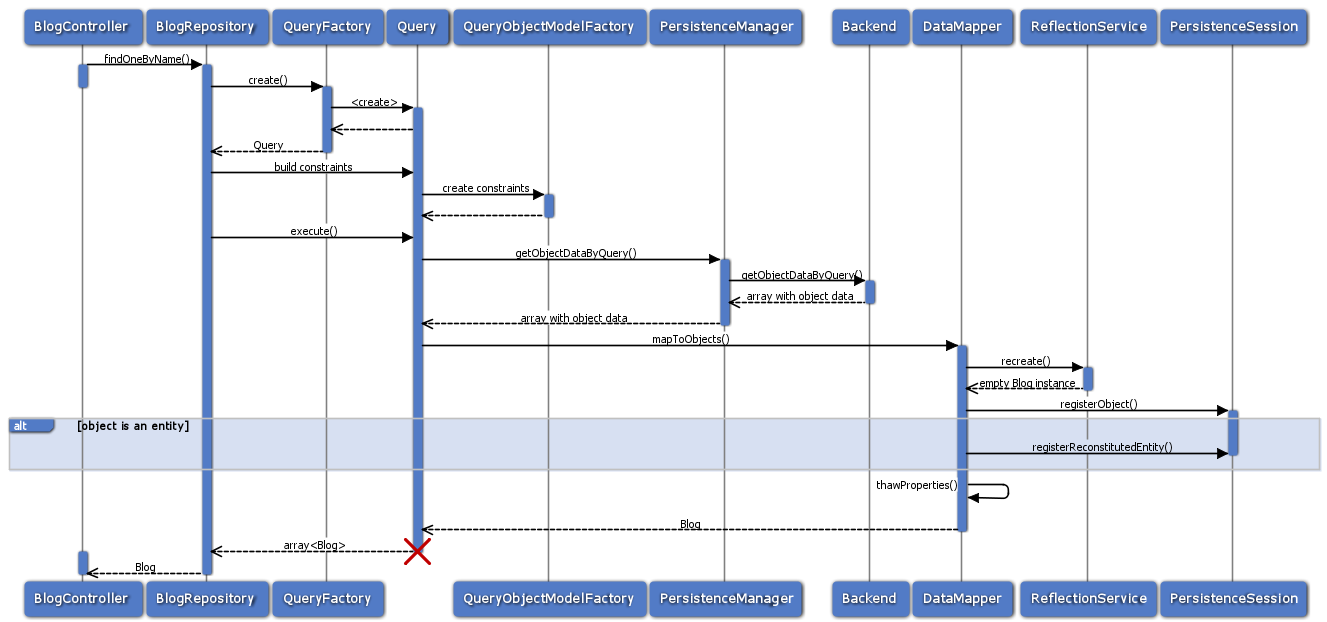
Object querying and reconstitution process
For the developer the complexity is hidden between the query’s execute() method and
the array of objects being returned.
- 4
An alternative would have been to do an implicit persist call before a query, but that seemed to be confusing.
- 5
https://doctrine-orm.readthedocs.org/en/latest/tutorials/embeddables.html
- 6
- 7
https://doctrine-orm.readthedocs.org/en/latest/reference/events.html
- 8
https://doctrine-orm.readthedocs.org/en/latest/reference/filters.html#filters
- 9